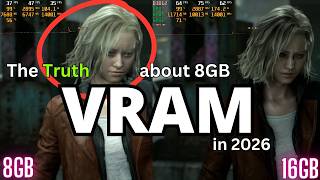Llms With 8gb 16gb - Detailed Analysis
Here's the one change that took mine from ~120 tok/s to 1200+ without a new GPU. TryHackMe just launched Cyber Security 101 ... Dave tests llama3.1 and llama3.2 using Ollama on a Raspberry Pi, a Herk Orion Mini PC, a 3970X, an M2 Mac Pro, and a ... I put a tiny MacBook Air between me and some ridiculously large local AI models... and it worked. Power Your Spring Essentials ... my latest project: Intuitive AI Academy, learn modern AI/ TurboQuant... the next big jump in local AI isn't a faster chip, but a different kind of compression. 🛡️Go to ... This video installs oLLM, a lightweight Python library for large-context
In this video I try to explain how easy it is to run an Here's the one change that let me use more RAM for Parts List - Affiliate Links RX 9060 XT PC used in the video CPU: Ryzen 5 9600X - Cooler: Silverstone Nova ... A 110 billion parameter AI model running on a laptop that even a 5090 can't handle. PLAUD NotePin ($10 OFF with the code ... Are you considering a new M2 or M1 Mac with Running a massive 26-billion parameter open-weights model on an everyday laptop used to be pure science fiction. Today, we ...
Step by step setup guide for a totally local
Photo Gallery